
About Me
👋 Hey there!
I’m a second-year Master’s student at Carnegie Mellon University (CMU). I previously graduated from Nanyang Technological University (NTU), where I had the opportunity to work under Prof. Ziwei Liu in S-Lab. At CMU, I’ve been involved with some exciting research at XuLab under Prof. Min Xu. I’m actively collaborating with Dr. Liang Pan on several research projects.
Right now, my primary focus is on 3D generation and world models. Beyond research, I love building cool projects and exploring music—I’m currently learning to play the guitar!
I’m always up for an interesting conversation, a brainstorming session, or a potential collaboration—feel free to connect!
Publications
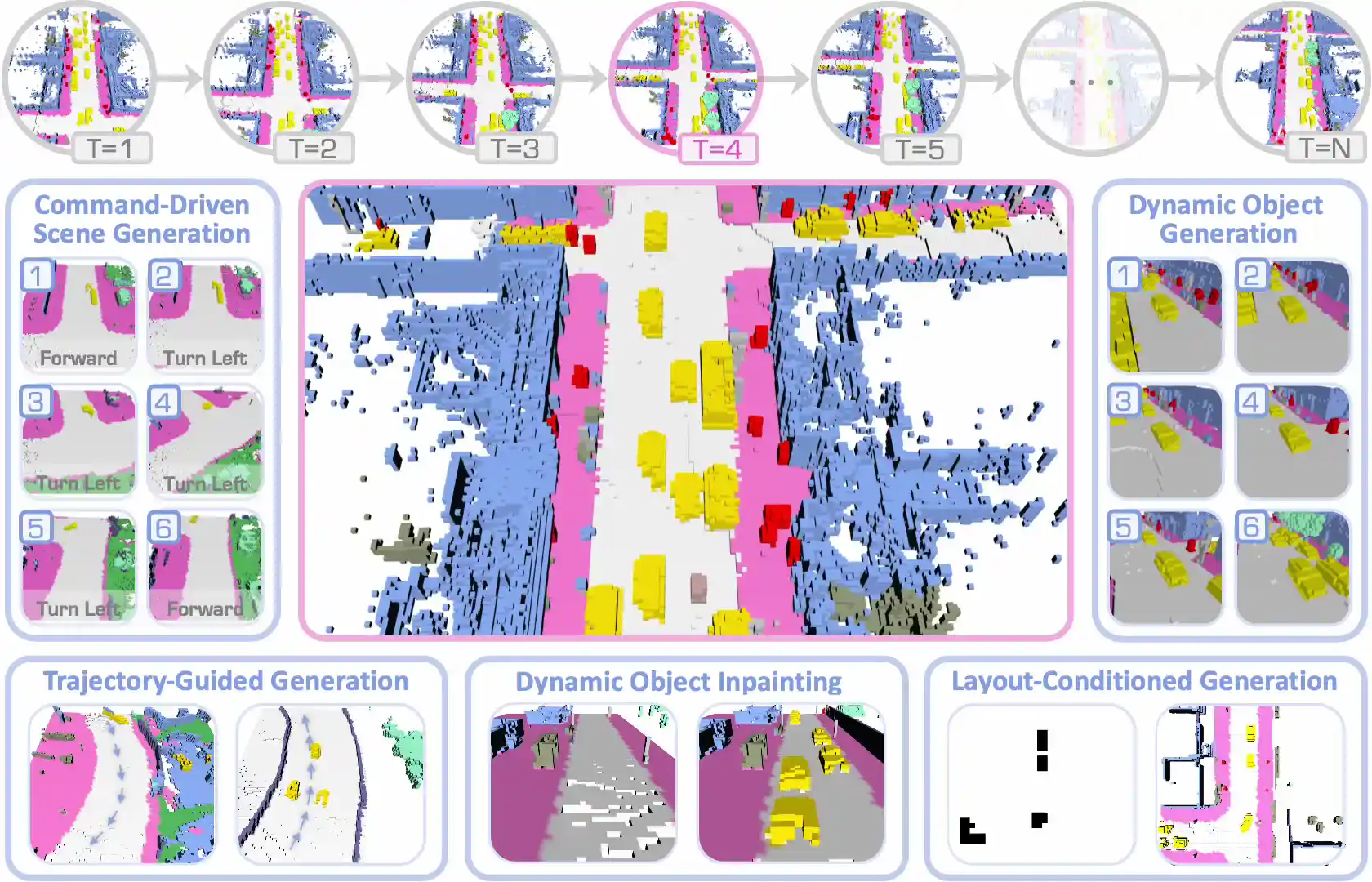
DynamicCity: Large-Scale 4D Occupancy Generation from Dynamic Scenes
Bian, Hengwei and Kong, Lingdong and Xie, Haozhe and Pan, Liang and Qiao, Yu and Liu, Ziwei
ICLR 2025 Spotlight
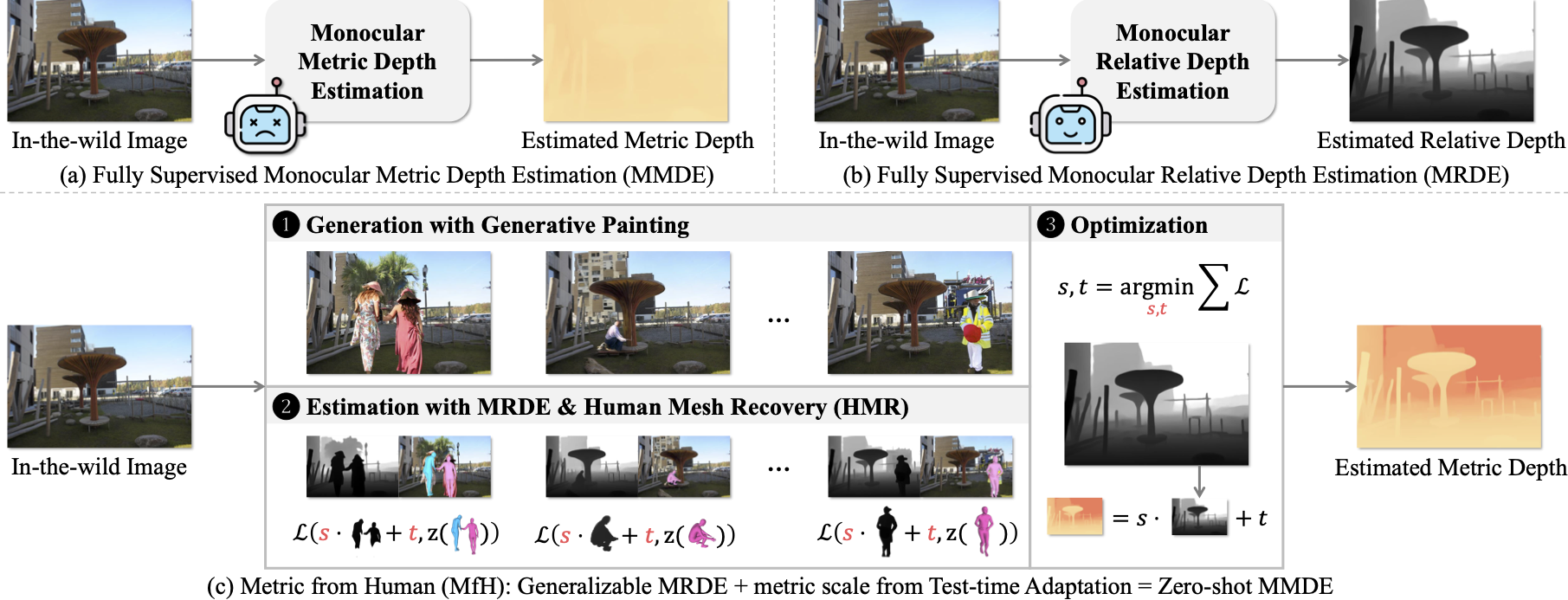
Metric from Human: Zero-shot Monocular Metric Depth Estimation via Test-time Adaptation
Zhao, Yizhou and Bian, Hengwei and Chen, Kaihua and Ji, Pengliang and Qu, Liao and Lin, Shao-yu and Yu, Weichen and Li, Haoran and Chen, Hao and Shen, Jun and Raj, Bhiksha and Xu, Min
NeurIPS 2024
SynesLM: A Unified Approach for Audio-visual Speech Recognition and Translation via Language Model and Synthetic Data
Lu, Yichen and Song, Jiaqi and Chang, Xuankai and Bian, Hengwei and Maiti, Soumi and Watanabe, Shinji
Interspeech 2024 Syndata4genai Workshop
CryoSAM: Training-free CryoET Tomogram Segmentation with Foundation Models
Zhao, Yizhou and Bian, Hengwei and Mu, Michael and Uddin, Mostofa R. and Li, Zhenyang and Li, Xiang and Wang, Tianyang and Xu, Min
MICCAI 2024
Bridging the Gap: A Unified Video Comprehension Framework for Moment Retrieval and Highlight Detection
Xiao, Yicheng and Luo, Zhuoyan and Liu, Yong and Ma, Yue and Bian, Hengwei and Ji, Yatai and Yang, Yujiu and Li, Xiu
CVPR 2024
Contact
- Email: hb.acad at outlook dot com